Appearance
进度条:[█████████░░░░░░░░░░░░░░░░],34%
Resourecs
- Learn Rust by Building Real Applications_哔哩哔哩_bilibili
- gavadinov/Learn-Rust-by-Building-Real-Applications (github.com)
- Learn Rust by Building Real Applications | Udemy
1.1 Course Introduction
无内容
1.2 What is Rust
Rust is a modern systems programming language.
- Memory Safe(内存安全,即便是最顶尖的 C/C++ 也无法 100% 去保证内存的安全,但 Rust 可以轻松做到)
- No Null(Rust 没有 Null 这个值,虽然开发上会麻烦一点,但是带来的保证了程序的稳定)
- No Exceptions
- Mondern Package Manager(Cargo)
- No Data Race(没有数据竞争)
1.3 Installing Rust
- 无内容
- 尽量不要使用 Windows 即可,我尝试使用 Mingw64 gdb 断点失败
1.4 Setting Up the Development Environment
- 无内容
- 我自己是 nvim + rust_analyzer,没什么问题
1.5 Cargo
Cargo new <path>将创建一个 rust 项目- rust 项目默认设置了 .git 仓库
- 修改
Cargo.toml可以配置依赖项目 - 这里添加一个
rand包作为依赖 - 可以到 crates.io 找到需要的第三方包
toml
[package]
name = "example"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
rand = "0.8.5"- 保存后运行一次
Cargo Build会自动下载好依赖包 - //////////////////////////////////////////
- 安装
Cargo install cargo-expand - 这个工具用于展开代码中的宏,相当于
gcc -E
2.2 Introduction:Mansual Memory ManageMent
- The Stack(栈内存)
- The Heap(堆内存)
- Pointers(指针)
- Smart Pointers(智能指针)
2.3 Stack
- Stack:一个进程内存中的特别区域用于存储由每个函数产生的变量
- 每个函数的内存称为 Stack frame (栈帧),是每个函数存储局部变量的地方
- 每个函数会调用一个新的 Stack 帧装载在栈顶的位置
- 栈上的每个变量必须在编译的时候就确定大小(如果想在栈上创建一个数组,那么就必须在精确指定它能容量的元素个数)
- 当函数退出的时候,栈帧就会被释放
- 开发者不需要关注栈中的内存管理,因为它是系统自动管理的

- 上面的伪代码演示了栈的运行原理,这个也就是 C 语言中所谓的形参和实参的实质了,当
stack_only函数退出的时候栈顶对应的帧就会被弹出,最后保留的变量 a 的值仍然是 2 - 栈的大小是有计算机架构,编译器,系统共同决定的
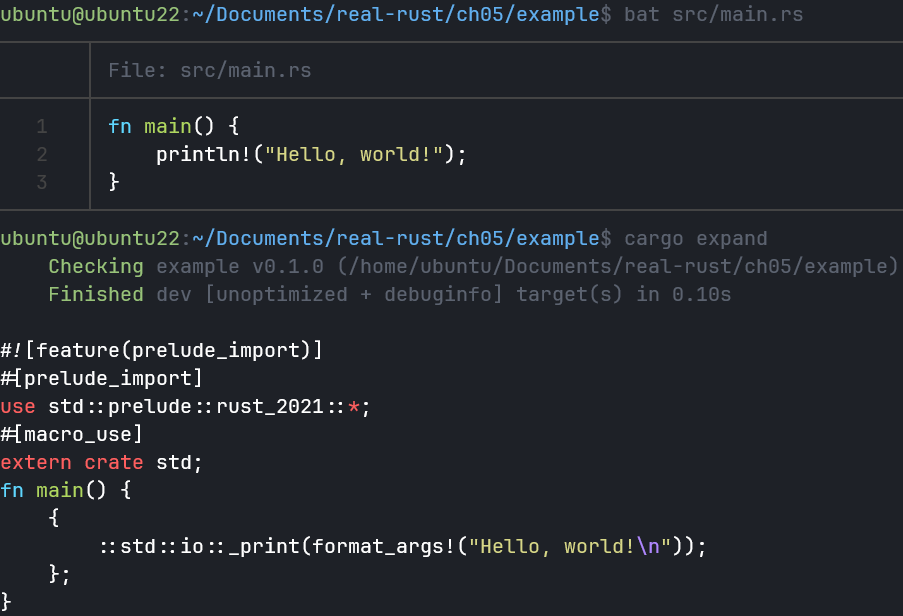
- 如果函数无限递归达到栈的极限,程序就会崩溃,也就是所谓的 Stack Overflow(栈溢出)异常
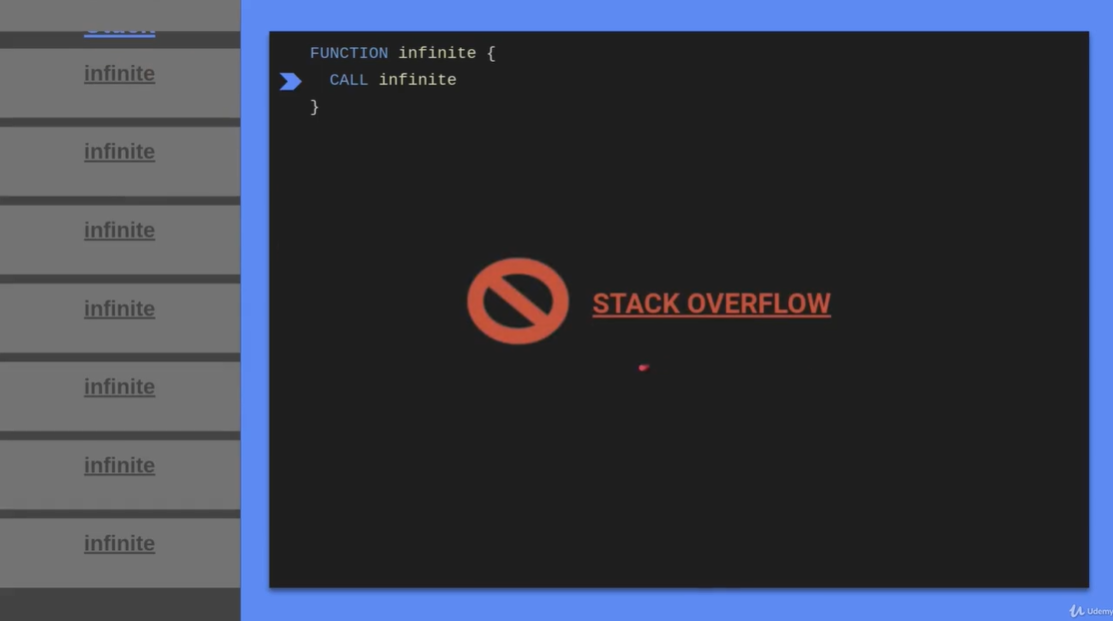
2.4 The Heap
- Heap:进程内存中不会自动管理的部分
- 必须手动申请手动释放,如果不手动释放的话,就会造成内存泄漏
- 堆可以存储大量的数据,其大小主要受到物理资源限制的影响
- 可以被任何函数,程序中的任何地方访问
- Heap 空间的调用资源耗费高,在开发中应当尽量避免使用
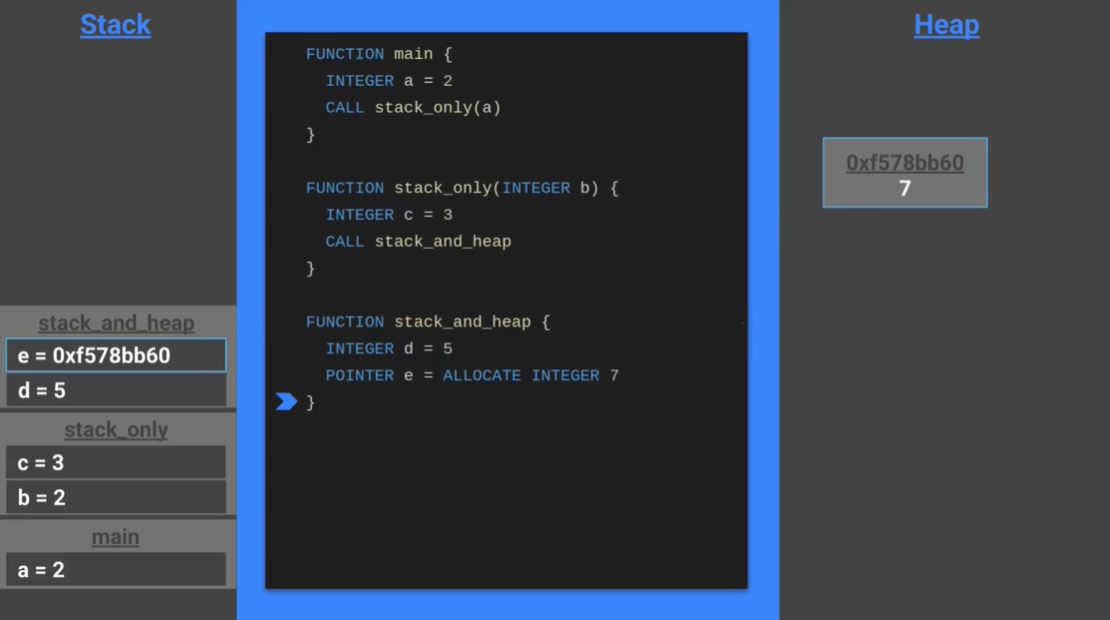
- 堆中申请的变量在栈中仅保存其指针
- 通过指针,我们可以像其他栈中的变量一样使用它
- 但是我们必须在使用完毕后手动释放堆中对应地址的空间
- 上图中如果
stack_and_heap的栈帧被弹出,我们就失去了变量e的指针,但是变量在 7 中仍然存在,直到程序的退出(即main的栈帧被弹出)
2.5 Smart Pointers
- 现代 C++ 中使用了智能指针
- 智能指针能够在保存指针的变量超出作用域的时候自动进行释放
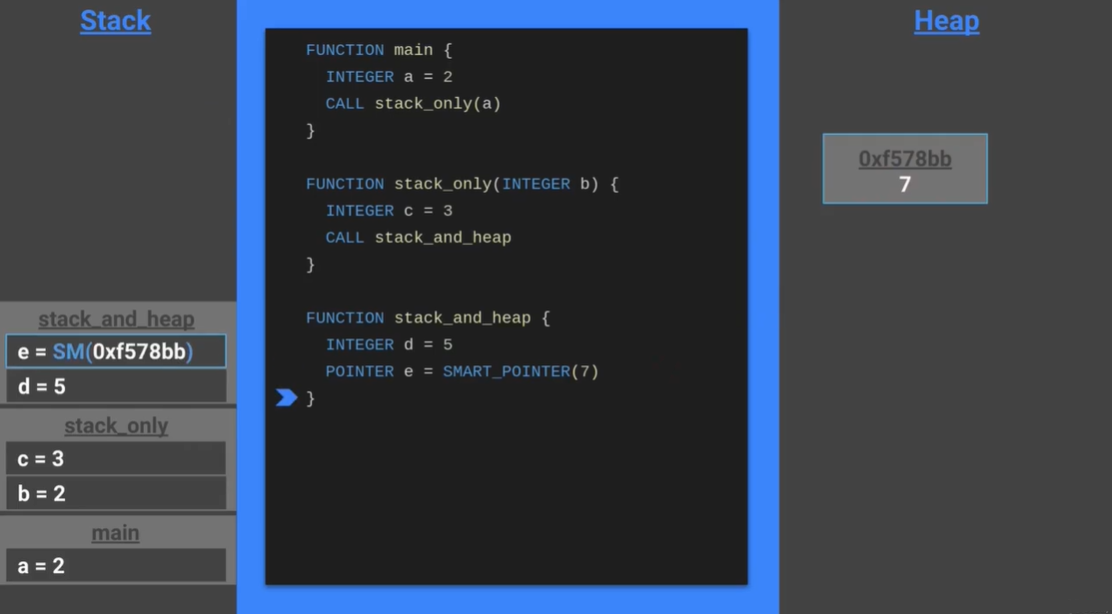
- 当
statck_and_heap的栈帧被弹出的时候,e对应的堆地址就会被释放
2.6 Explore the Memory Layout in GDB
- Mingw64 gdb 断点无用,切换到 Ubuntu 没有问题
- 讲师的 GDB 装了 https://pwndbg.com/ 这个插件
- 几个 GDB 指令说明一下:
b:用来设置断点bt:用来打印函数调用栈info locals:打印当前行所在位置的局部变量,就是栈顶栈帧的局部变量info args:同理打印栈顶栈帧函数获得的参数n继续执行下一行x打印对应堆区内存中的值c程序继续执行到下一个断点,或者结束
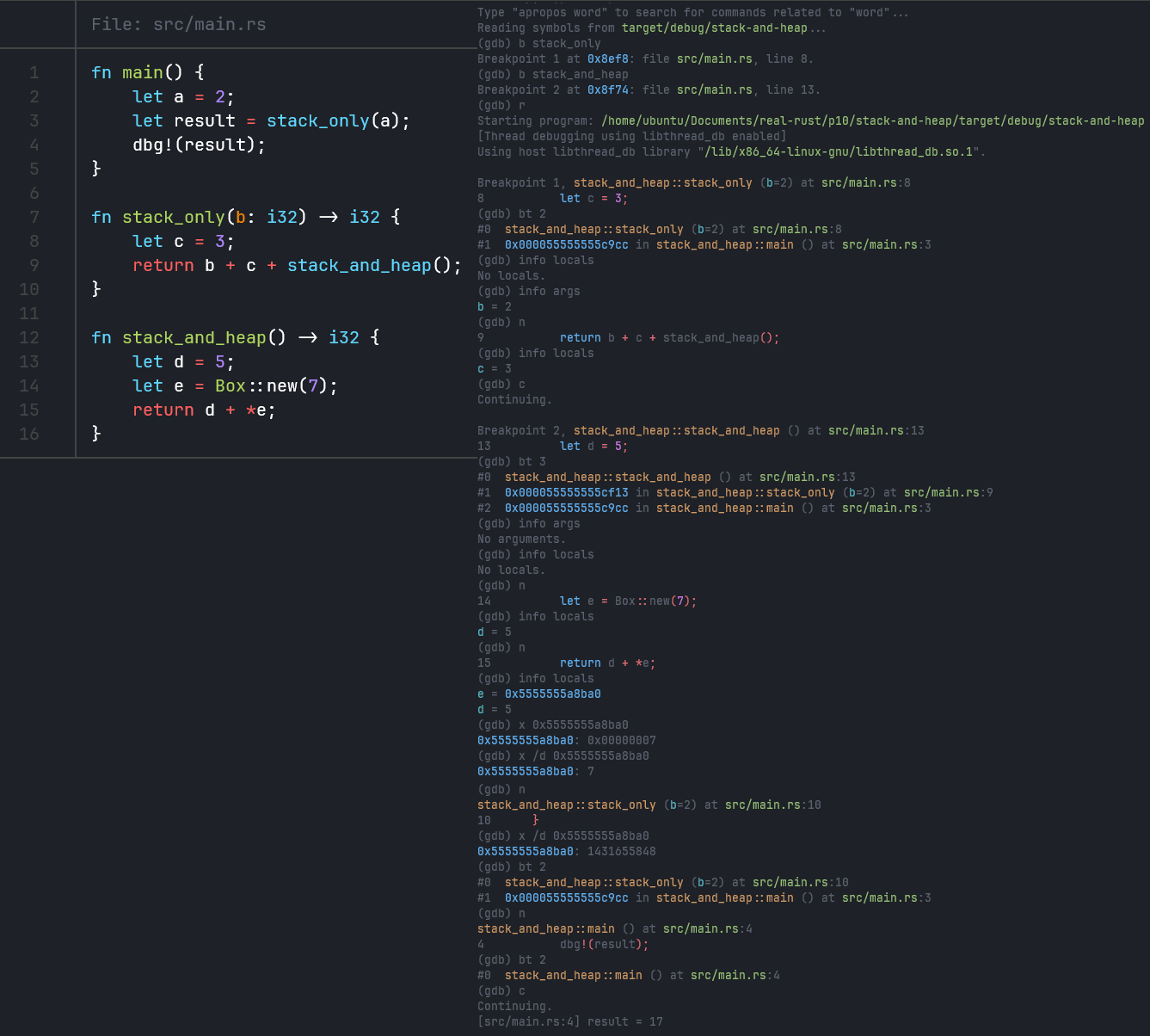
- 讲师的栈区释放后内存打印内容是 0,我的 Ubuntu 中是随机数值,这和操作系统使用内存的方式可能有关,但不是 7 就说明已经正常释放了
3.2 Introduction:Building Command Line Application
- 构建一个简单的命令行程序
- 从用户输入获取数据,并打印相关内容
- 内容涵盖最基本的概念,例如函数,基本数据类型,标准库,内存所有权
- 程序是一个火星重量计算器,用户输入他在🌍️地球上的体重,程序会打印他在火星上的体重
3.3 Basic Data Types
- Rust 有四种基本数据类型:
- Booleans
- Characters
- Integers
- Floats

- 上图中,
u代表unsigned即无符号整型数据,i代表有符号 816等数字代表位数大小,上图中一个空格占用 1 字节usize和isize则会依据计算机架构自动匹配大小,在 32 位机器上就是u32,i32,即 8 字节大小- 一个 char 存储一个标准的 Unicode 字符,它的大小始终是 4 字节
- 这点和 C 语言的 char 存储 1 字节的 ascii 很不一样
- 所以 rust 的 char 用来存储 ascii 字符要记住有空间的浪费(应当采用
u8)
3.4 Functions
fn关键字指定一个函数main函数名有特殊的意义,它是程序的入口- rust 使用 lower snake case 作为函数命名规则,例如
foo_bar - 因为函数栈帧必须在构建的时候确定大小,所以函数的参数必须指定数据类型(不能像其他语言那样编译器推导吗🤔)
- rust 函数使用
return var;返回数据,但是也可以用无return后面不加分号的最后一句表达式作为返回值,当然想要在前面的代码中提前返回,还是需要return - 当前版本的代码
src/main.rs:
rs
fn main() {
println!("Hello, world!");
calculate_weight_on_mars(100.0);
}
fn calculate_weight_on_mars(weight: f32) -> f32 {
50.0
}- 此时编译运行,可能警告
weight未使用
3.5 Macros
println!不是函数,是一个宏- 宏用于元编程,是一种编写更多代码的方式
- 函数签名必须声明函数的所有参数和类型
- 而宏是可以具有可变数量的参数和不同类型的参数
- 宏的缺点是定义比函数定义更加复杂,因为需要编写更多代码检查风险,使得程序更难维护和阅读
pirntln!宏函数第一个字符串可以作为format字符串,使用{}作为占位符,将后序参数插入打印,类似 C 语言的 printf 但不要求指定数据类型- 想要知道宏是怎么修改你的代码的,可以使用
cargo expand指令,在上面安装过了 - 自己 expand 出来的代码和讲师的不太一样,可能和 rust 的版本有关
- 体重转换公式如下:

- 目前版本的代码如下
src/main.rs:
rs
fn main() {
println!("Weight on Mars: {}kg", calculate_weight_on_mars(100.0));
}
fn calculate_weight_on_mars(weight: f32) -> f32 {
(weight / 9.81) * 3.711
}3.6 Mutablility
- rust 中变量使用
let关键词声明 - 不必指定类型,会依据赋值推断
- 所有变量在默认情况下是不可变的
- 必须显式声明变量可变,使用
let mut - 当前的版本代码
src/main.rs:
rs
fn main() {
let mut mars_weight = calculate_weight_on_mars(100.0);
mars_weight = mars_weight * 1000.0;
println!("Weight on Mars: {}kg", mars_weight);
}
fn calculate_weight_on_mars(weight: f32) -> f32 {
(weight / 9.81) * 3.711
}3.7 The Standard Library
- Rust 的标准库包含了一些常用的数据结构,以及我们需要的 IO 库
- 非标准的库(即第三方库)在 cartes.io 中,需要下载使用
- 可以在 doc.rust-lang.org/std/ 阅读标准库的文档
- 从 std 的列表找到我们要用的 io 库,点击进入 std::io 阅读详细文档
- 我们现在需要的是 input 用户输入,找到 input adn output 章节
- 我们已经使用 println! 来调用标准输出了
- 从示例代码,我们可以看到可以通过
io::stdin().read_line()函数读取一行输入 - 要使用标准库,需要在代码头部引入库使用
use std::io; - nvim 装了 rust-tools.nvim 插件后,可以像 C 语言那样通过
<C-]>跳转源代码(<C-o>返回),如果和我一样使用 NvChad,也能像 VSCode 那样 Ctrl + 鼠标点进跳转 - 我们使用 String 类型数据接收用户输入,这是一个封装的数据类型,因为用户输入字符串没有固定的大小,所以它使用的堆内存空间
- 直接将用户输入变量
input传入read_line编译器报错,提醒你修改成&mnt input,先按照编译器的建议修改,这个内容要学习所有权后才知道 - 目前版本的代码如下
src/main.rs:
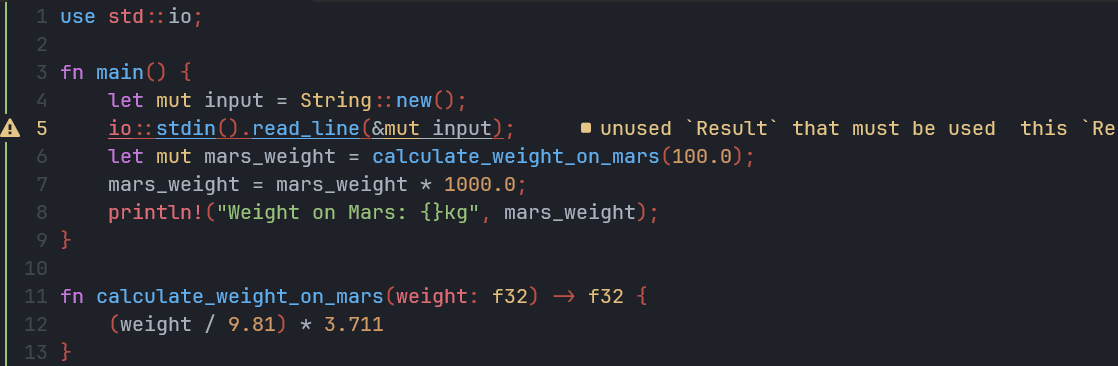
read_line返回一个Result类型的值,这个值没有被使用(它必须被使用),所以 Analyzer 会提醒你,不过可以先忽视它
3.8 Ownership
- 所有权是其他语言没有的概念,是 Think in Rust 的要点
- 所有权有三个⭐非常重要的原则:
- 每个变量值都被一个变量所拥有
- 当所有者离开作用域,值会被释放
- 一个值只能被一个所有者拥有
- 查看 3.7 中的代码,当
String::new()构造一个值后,它被变量input所拥有 - 虽然我们不清楚
String,但是从其他语言的编程经验可以猜到new()是在堆内存申请空间的 - 当
input走出作用域的时候,对应的堆内存空间将被释放回收 - 这和之前 2.5 学过的智能指针非常相似
- 编译器在
input走出作用域的时候,编译器实际上会自动在该字符串变量上调用drop函数,这个函数和其他语言的析构函数非常相似 - 依据第 3 条原则,一次只能被一个所有者拥有,这是为了解决其他语言,比如 C 语言中的双重释放问题。如果两个指针指向了堆内存的同一块空间地址,那么在程序复杂的时候(比如分支特别多的时候),你的代码可能会对两个指针都进行释放。这就造成了双重释放的问题。这是一个非常危险的程序漏洞,一方面,你的 C 编译器不会认为你的代码有任何问题,另一方面,如果你第一次释放空间后,该地址的内存已经被程序中的其他地方的变量使用了,当再次进行释放的时候,会造成对数据的破坏,更要命的是,因为运行情况的不同(即内存使用情况的不同),这个 bug 产生的错误会不一样,使得 bug 很难被定位。
- 正是因为第三条这个原则,当
input作为右值赋值给其他String数据类型的变量的时候,产生的是 ▶『移动』,即把变量值从input转移到新的变量中,再次使用input的时候,它没有任何数据,编译器会提示错误 - 如果想要实现
input和它赋值的对象比如let mut s = input;都能保留值,就需要实现Copy的 trait,这和 C++ 等语言对=操作符的重载很像,但要知道,我们使用的是深拷贝的后的数据,它的修改不会影响到原先的值。rust 的基础数据类型都实现了Copy的 trait,所以对它们使用=赋值,不会产生『移动』。 - 但是这三条所有权的原则,让函数参数传递非常困难,因为当我们在
some_fn函数中直接传入input的时候,实际上会发生实参对形参的赋值,在 Rust 中,这个行为属于『移动』,那么变量值实际上会从main的栈帧移动到fun函数的栈帧,并随着some_fn的栈帧被弹出而离开作用域而被释放,如果后序代码再次使用它(实际上main中也已经没有它的所有者),编译器就会报错,显然这个不符合我们日常使用函数的习惯,所以有了『借用』和『引用』
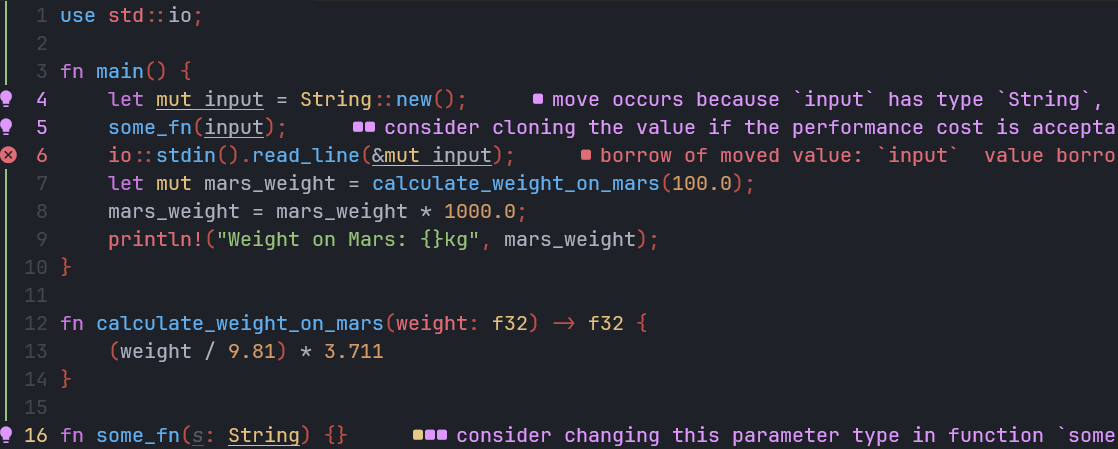
- 目前的代码是没法通过的,在第 6 行中,编译器会提示借用的了一个已经被移动的值,而且在第 5 行,编译器也提示你考虑使用拷贝后的值进行传递
3.9 References and Borrowing
- 为了在不进行『转移』的情况下,将变量作为函数参数传递,rust 有一个功能称作 ▶『引用』,修改上面的
some_fn代码:
rs
fn some_fn(s: &String) {}- 此时
s变量保存的是对实参的引用,它不会夺取实参的所有权,同样调用函数的也需要修改成some_fn(&input) - 引用默认是不能被修改的,把
&替换成&mut使得其可以被修改s: &mut String,当然传入参数也必须是&mut input,此时则被称作为 ▶『借用』 - 如果对一个值进行了『借用』,那么就不能再被『引用/借用』了
- 这是为了防止产生数据竞争,当我们单线程编程的时候,我们可以确定内存特定位置的数据在某个步骤时的值。但是切换到多线程后,由于线程的执行顺序是不确定的,所以如果多个线程都在修改同一个地方的数据,数据的编变化也难以预料。会造成数据竞争,所以有互斥锁等方法解决,但它不是强制使用的,如果开发者忘记使用,则可能造成 bug,这也是为什么一些单线程并发模式受到欢迎的原因吧
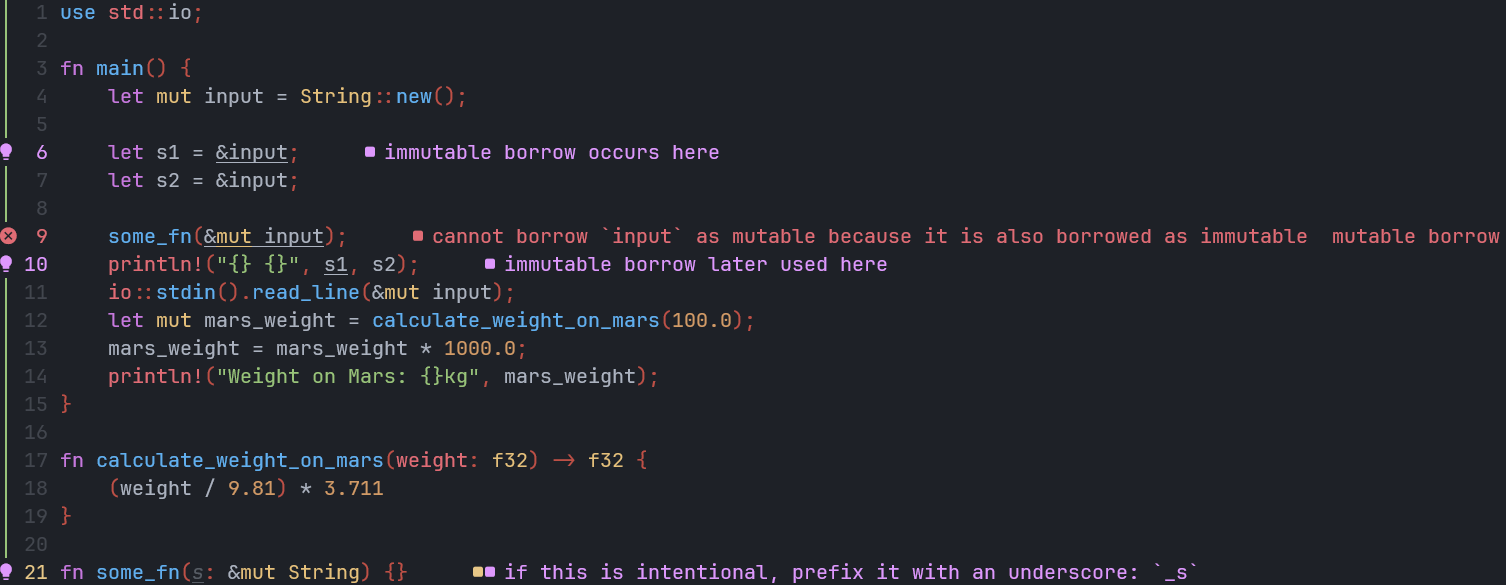
- 上图中
s1和s2是对input的引用,此时,input就不能再被其他变量借用了 - 其实简单点打个比方:
- 比如你有一个游戏机,你妈妈想要看一下,那么你就可以给她看一下,你爸爸想看,你也可以给他看,不管是谁想看,都可以看,反之也不会被拿走;
- 但是如果你把它借给小明了,你妈妈想要看一下就不可以了(或者说因为你妈妈想要看,所以就不允许你借给小明);
- 当然,如果是在借给小明前给妈妈看一下当然是可以的;
- 而且你只能把游戏机借给一个人,除非你再买个一样的(复制一份)
3.10 Explore the Ownership and Borrowing in GDB
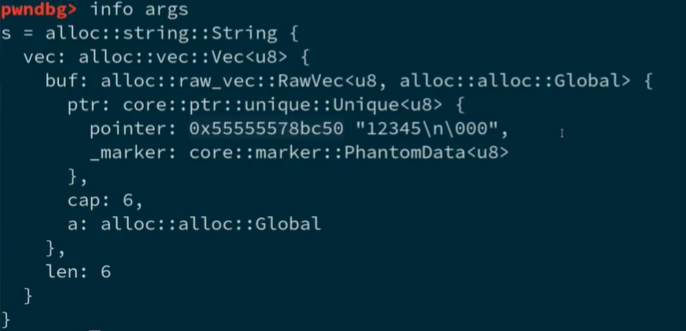
- 通过
info args查看引用作为函数传递,参数其实就是一个指针 - 同样,查看直接作为参数进行的传递,参数是是完整的 String 类型数据,这个类型的数据包含了一个指针,指向内存空间保存数据的地址
3.11 Finishing Touches
io::stdin().read_line()返回一个Result类型数据,Result有两个状态是OK和ERR。- 它有一个
unwrap()方法,这个方法会确定:如果Result进入ERR状态,程序就会进入终止 String.trim()方法可以清除字符串头尾的空格debug!宏可以打印数据的时候显示行号和变量名parse()可以解析字符串到基本数据类型,但是需要对赋值的对象显式声明类型,而且它的返回值也是Result类型数据,需要调用unwrap(),处理错误
rs
use std::io;
fn main() {
println!("Enter your weight (kg):");
let mut input = String::new();
io::stdin().read_line(&mut input).unwrap();
let weight: f32 = input.trim().parse().unwrap();
dbg!(weight);
let mars_weight = calculate_weight_on_mars(weight);
println!("Weight on Mars: {}kg", mars_weight);
}
fn calculate_weight_on_mars(weight: f32) -> f32 {
(weight / 9.81) * 3.711
}4.2 Introduction: Building HTTP Server from Scrath
- 这个模块将学习构建一个 HTTP 服务器
- 但这个服务器不是以性能学习为目的的
4.3 The HTTP Protocol and the Architecture of Our Server
- 我们将实现的是 HTTP/1.1 协议
- 它是第七层协议(参考ISO标准通讯模型)
- 它通过 TCP 协议发送
- 基于消息传递
- 客户端发送给服务器的称作为请求(request)
- 服务器回复客户端的称作为响应(response)

- 因为这是一个简单的 HTTP 服务器,所以会专注在上面标绿的部分的内容
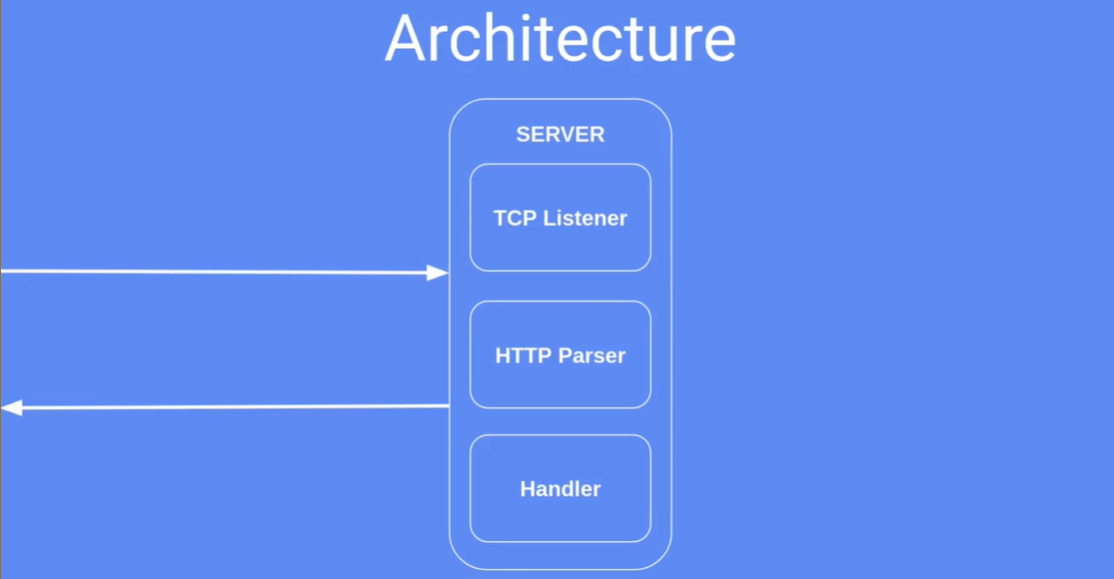
- 一个 HTTP 服务器的基本结构是:
- TCP 监听:等待获取用户的请求
- HTTP 解析器:大部分的代码都在这个部分,它用来解析获取到请求的包的结构(指解包)
- 处理方法:依据请求内容处理